API-плейбук для разработчиков и AI-агентов
Туториалы, сравнения и кейсы — чтобы подкреплять ответы LLM источниками, собирать пайплайны агентов и выводить AI-фичи в продакшен.

Бесплатные API IP-геолокации в 2026: точность, лимиты и когда стоит платить
IP-геолокация выглядит решённой задачей, пока не прочитаешь мелкий шрифт: лицензии только для некоммерческих проектов, бесплатные тарифы только по HTTP, лимит 100 запросов в месяц или 'бесплатные' планы, возвращающие только страну. Этот гид сравнивает реальные бесплатные варианты в 2026 — самостоятельный хостинг GeoLite2, ip-api.com, IPinfo, ipstack, ipgeolocation.io и API Pick — с честными цифрами точности и гидом по выбору.

Как построить агента инвестиционного анализа: рынки, фундаментал, SEC и экономические данные в одном API
Агенту инвестиционного анализа нужны пять разных слоёв данных — цены, фундаментал, отчётность, макро и новости — и каждый из них обычно означает отдельного поставщика, ключ и схему. Вот как завязать все пять на один набор эндпоинтов, с рабочим кодом и расчётом стоимости.

Строим агента CVE и аналитики уязвимостей: CISA KEV, NVD, EPSS и MITRE ATT&CK в одном API
Любая команда безопасности тонет в CVE. Сигнал — не серьёзность, а то, эксплуатируется ли уязвимость и насколько это вероятно. Вот как построить агента, который сплавляет NVD, CISA KEV, EPSS и ATT&CK, чтобы ответить на вопрос «что патчить в первую очередь?»

API рыночных данных в реальном времени для AI-агентов: акции, крипта, форекс и ETF в одном эндпоинте
Большинство API рыночных данных строились под дашборды и квант-конвейеры, а не под LLM-агентов. Вот что меняется, когда ваш потребитель — модель: запросы на естественном языке, один формат для всех классов активов, тарификация только за успех — и как API Pick Markets сравнивается с устоявшимися игроками.

API фундаментальных показателей компаний: баланс, денежный поток и сделки инсайдеров для финансовых агентов
Цены говорят, что думает рынок; фундаментал говорит, прав ли он. Вот API фундаментальных показателей, сформированный под AI-агентов — отчётность, дивиденды и сделки инсайдеров в одном эндпоинте — и как он сравнивается с сырым SEC EDGAR и поставщиками API отчётности.

API экономических данных для AI-агентов: FRED, BLS, World Bank и IMF в одном вызове
API FRED превосходен — и при этом США-центричен, завязан на ID серий и является лишь одним из нескольких макроисточников, которые вам в итоге понадобятся. Вот эндпоинт экономических данных, который сплавляет FRED, BLS, World Bank и IMF за одним вызовом на естественном языке для макроосознанных агентов.

Лучшие Web Search API для AI-агентов в 2026 году (сравнение)
Bing Search ушёл в отставку в 2025 году, и десяток agent-native search API бросились его заменять. Вот практическая, актуальная карта того, кто что возвращает, кто как тарифицирует и какую API вшить в своего агента.

Exa vs Tavily: какую Search API выбрать для AI-агента? (2026)
Exa и Tavily — два названия, которые приходят на ум первыми, когда вы вшиваете поиск в агента. Они решают одну задачу противоположными способами. Вот честное прямое сравнение с реальными формами API и ценами 2026 года.

Agentic Search vs SERP-скрейпинг: почему агентам нужна другая API
Двадцать лет search API означало «скрейпить страницу результатов Google». AI-агенты сломали это допущение. Вот что такое agentic search на самом деле, почему он появился и когда старая модель SERP всё ещё имеет смысл.

API поиска патентных заявок USPTO (ODP) — и 5 альтернатив мёртвому Google Patents API
Google Patents Public Datasets вышел из эксплуатации без документированной замены, а USPTO мигрировал PEDS в новый Open Data Portal в середине 2026 года, ломая пайплайны по пути. Вот что реально работает в 2026 году для prior-art, FTO и IP-research нагрузок — шесть альтернатив, бок о бок.

Как построить агента для обзора научной литературы и не упереться в rate-limit
Соберите сегодня агента для обзора литературы поверх сырых arXiv + PubMed + Semantic Scholar — и упрётесь в 429-е раньше, чем разберёте десять статей. Разбираем, почему лимиты стали жёстче, что на самом деле делают под капотом PaperQA / Undermind, и рабочий паттерн, который переживает реальную сессию обзора.
Polymarket vs Kalshi API: руководство разработчика бок о бок (Auth, CLOB, WebSocket, исторические данные)
Polymarket и Kalshi реализуют один и тот же примитив — yes/no контракты на CLOB — через совершенно разные API. Один требует EIP-712-подписей и кошелька Polygon; другой — это REST-эндпоинт с опциональным FIX. Если вы строите forecasting-агента, арбитражного бота или монитор smart-money, вот руководство бок о бок, которое уже должно было существовать.

Поиск прецедентного права UK с привязкой к цитатам после Ayinde v Haringey
Ayinde v Haringey за одну ночь изменило расклад для британского юридического ИИ. Барристер сослался на пять фейковых дел, сгенерированных LLM, и был направлен в Bar Standards Board. У галлюцинированных цитат теперь есть последствия для профессионального поведения. Вот руководство разработчика по построению поиска прецедентного права UK с привязкой к цитатам — TNA Find Case Law, legislation.gov.uk, парсинг нейтральных цитат и как подключить всё это к рабочему агенту.

Связываем ClinicalTrials.gov v2 + openFDA + ChEMBL в license-clean эндпоинт лекарственной аналитики
Фарма-R&D, medical-AI стартапы и команды фармаконадзора хотят одного: эндпоинт, который тянет клинические исследования, лейблы, нежелательные явления и биоактивность license-clean способом. Вот рабочая архитектура — и подводные люки, которые удивляли команды в продакшене.

Собираем research-агента на Search + URL Extract (Claude tool use, от начала до конца)
Большинство туториалов про 'AI research-агента' заканчиваются на 'вот определение инструмента'. Этот шипит рабочего агента: вопрос на входе, ответ с цитатами на выходе. Поиск, извлечение, рассуждение, цитаты — всё меньше чем в 120 строках Python.

Строим агента для due diligence по отчётности SEC (10-K, 10-Q, 8-K, earnings)
Чтение 10-K — это в основном Ctrl+F. Делать это для пятидесяти компаний — уже работа. Замените скучные 80% агентом search-and-extract поверх SEC EDGAR — оставьте 20% важного человеку-аналитику.

Почему API должны брать деньги только за успех — аргумент в пользу тарификации по HTTP 200
Большинство API берёт деньги за каждый тарифицируемый вызов. ИИ-агенты постоянно ретраят при нестабильных апстрим-сервисах — а значит, легаси-модель 'берём всегда' фактически облагает налогом устойчивость. Вот аргумент в пользу оплаты только при HTTP 200 и что это меняет в дизайне агентов.

Tavily vs Exa vs Serper vs API Pick: какую Web-Search API выбрать для LLM?
Tavily, Exa, Serper и API Pick — все обещают быть слоем поиска для вашего LLM. Они заметно отличаются по формату, фильтрам и тарификации. Прямое сравнение от инженера, который шипит агенты.

Firecrawl vs Jina Reader vs API Pick: сравнение API для извлечения контента из URL
Если вы хоть раз шипили агента, читающего список URL и делающего саммари, налог на чистку URL вам знаком. Firecrawl, Jina Reader и API Pick Extract решают это по-разному. Практический вывод.
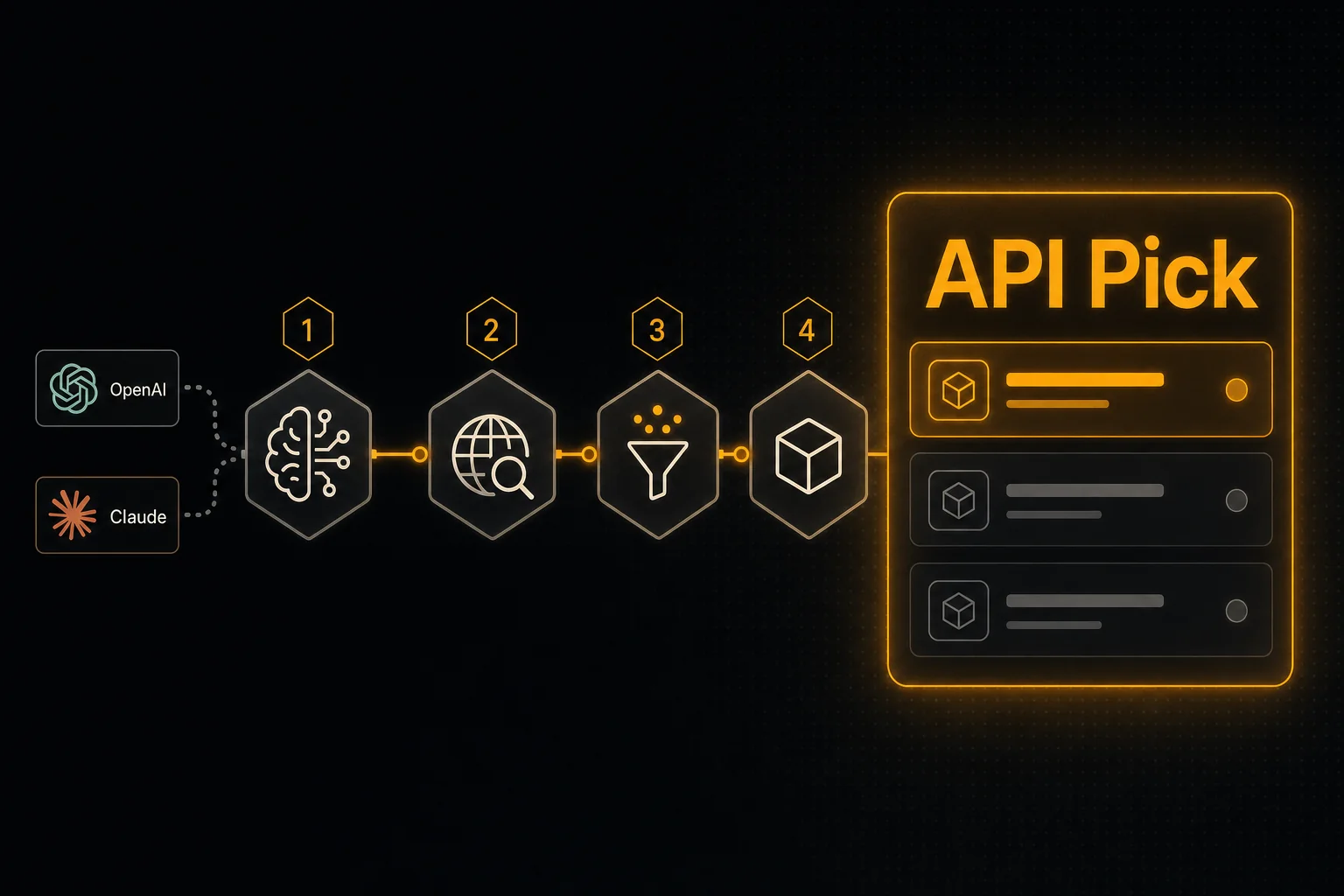
Как добавить веб-поиск в реальном времени в OpenAI- или Claude-агента за 4 шага
Хотите, чтобы агент опирался на свежую информацию? Нужны ровно две вещи: search API, возвращающий LLM-friendly snippets, и описание инструмента, которое модель сможет вызвать. Этот гайд делает обе за 4 шага.

Утренний brief-агент на News Search API
Основатели, PM и аналитики хотят одного и того же в 8 утра: чистый дайджест того, что изменилось за ночь. С News Search API, LLM и cron-платформой это собирается за полдня.