Cẩm nang API cho nhà phát triển & AI Agent
Hướng dẫn, so sánh và trường hợp sử dụng để neo câu trả lời của LLM, xây dựng quy trình agent và đưa tính năng AI lên production.

Cách xây dựng tác tử nghiên cứu đầu tư: thị trường, cơ bản, SEC & dữ liệu kinh tế trong một API duy nhất
Một tác tử nghiên cứu đầu tư cần năm lớp dữ liệu khác nhau — giá, cơ bản, hồ sơ, vĩ mô và tin tức — mỗi lớp thường là một nhà cung cấp, một key và một schema riêng. Đây là cách nối cả năm phía sau một bộ endpoint, kèm mã chạy được và bài toán chi phí.

Xây dựng tác tử tình báo CVE & lỗ hổng: CISA KEV, NVD, EPSS và MITRE ATT&CK trong một API duy nhất
Mọi đội bảo mật đều chìm trong CVE. Tín hiệu không phải là mức độ nghiêm trọng — mà là liệu một lỗ hổng có đang bị khai thác hay không và khả năng đó lớn đến đâu. Đây là cách xây dựng một tác tử hợp nhất NVD, CISA KEV, EPSS và ATT&CK để trả lời câu hỏi 'tôi nên vá gì trước?'

API dữ liệu thị trường thời gian thực cho AI Agent: Cổ phiếu, Crypto, Forex & ETF trong một endpoint
Hầu hết các API dữ liệu thị trường được xây dựng cho dashboard và pipeline định lượng, không phải cho AI agent. Đây là những gì thay đổi khi người dùng của bạn là một mô hình — truy vấn ngôn ngữ tự nhiên, một định dạng duy nhất cho mọi loại tài sản, tính phí chỉ-khi-thành-công — và cách API Pick Markets so sánh với các tên tuổi lớn.

API Cơ bản Doanh nghiệp: Bảng cân đối kế toán, Dòng tiền & Giao dịch nội bộ cho tác tử tài chính
Giá cho biết thị trường nghĩ gì; còn các yếu tố cơ bản cho biết thị trường đúng hay sai. Đây là một API cơ bản được định hình cho tác tử AI — các báo cáo, cổ tức và giao dịch nội bộ trong một endpoint — và cách nó so với SEC EDGAR thô và các nhà cung cấp API báo cáo.

API dữ liệu kinh tế cho tác nhân AI: FRED, BLS, Ngân hàng Thế giới & IMF trong một lệnh gọi
API của FRED rất tuyệt — và lấy Hoa Kỳ làm trung tâm, dựa trên ID chuỗi, và là một trong nhiều nguồn vĩ mô mà bạn rốt cuộc sẽ cần. Đây là một endpoint dữ liệu kinh tế hợp nhất FRED, BLS, Ngân hàng Thế giới và IMF sau một lệnh gọi ngôn ngữ tự nhiên duy nhất cho các tác nhân nhận thức về vĩ mô.

API Web Search tốt nhất cho AI Agent năm 2026 (So sánh)
Bing Search ngừng hoạt động năm 2025 và cả chục API tìm kiếm thuần agent lao vào thay thế nó. Đây là bản đồ thực tế, cập nhật về việc ai trả về cái gì, ai tính phí ra sao và nên nối cái nào vào agent của bạn.

Exa vs Tavily: nên chọn API tìm kiếm nào cho AI agent của bạn? (2026)
Exa và Tavily là hai cái tên xuất hiện đầu tiên khi bạn ghép tìm kiếm vào một agent. Chúng giải quyết cùng một công việc theo hai hướng ngược nhau. Đây là màn so kè thẳng thắn, với hình dạng API thực tế và giá năm 2026.

Agentic search vs SERP scraping: vì sao agent cần một API khác
Suốt hai mươi năm, một API tìm kiếm có nghĩa là 'cào trang kết quả của Google'. Các AI agent đã phá vỡ giả định đó. Đây là bản chất thực sự của agentic search, vì sao nó xuất hiện, và khi nào mô hình SERP cũ vẫn còn hợp lý.

API của Google Patents đã chết — 6 giải pháp thay thế cho tìm kiếm tình trạng kỹ thuật đã biết và quyền tự do khai thác
Google Patents Public Datasets bị gỡ bỏ mà không có bản thay thế được ghi tài liệu, và USPTO đã di chuyển PEDS sang một Open Data Portal mới vào giữa năm 2026, làm hỏng các pipeline trên đường đi. Đây là những gì thực sự hoạt động vào năm 2026 cho các tác vụ tình trạng kỹ thuật đã biết, FTO và nghiên cứu sở hữu trí tuệ — sáu giải pháp thay thế, đặt cạnh nhau.

Cách xây dựng agent tổng quan tài liệu khoa học mà không bị giới hạn tần suất
Dựng một agent tổng quan tài liệu trực tiếp trên arXiv + PubMed + Semantic Scholar thô ngay hôm nay, bạn sẽ dính lỗi 429 trước khi đọc xong mười bài báo. Đây là lý do các giới hạn tần suất trở nên tệ hơn, PaperQA / Undermind thực sự làm gì bên trong, và một mẫu thiết kế hoạt động được, sống sót qua một phiên tổng quan thực tế.
API Polymarket vs Kalshi: Hướng dẫn so sánh trực tiếp cho lập trình viên (Auth, CLOB, WebSocket, dữ liệu lịch sử)
Polymarket và Kalshi vận hành cùng một nguyên thủy — hợp đồng có/không trên một CLOB — nhưng qua những API hoàn toàn khác nhau. Một bên đòi chữ ký EIP-712 và một ví Polygon; bên kia là một endpoint REST với FIX tùy chọn. Nếu bạn đang xây một agent dự báo, một bot arbitrage, hay một bộ theo dõi dòng tiền thông minh, đây là hướng dẫn so sánh trực tiếp lẽ ra đã phải tồn tại.

Truy xuất án lệ Vương quốc Anh có căn cứ trích dẫn sau vụ Ayinde v Haringey
Vụ Ayinde v Haringey đã thay đổi cục diện của AI pháp lý ở Anh chỉ sau một đêm. Một barrister đã trích dẫn năm vụ án giả do một LLM tạo ra và bị chuyển sang Bar Standards Board. Trích dẫn ảo giác giờ đây kéo theo hậu quả về đạo đức nghề nghiệp. Đây là hướng dẫn dành cho lập trình viên để xây dựng truy xuất án lệ Vương quốc Anh có căn cứ trích dẫn — TNA Find Case Law, legislation.gov.uk, phân tích cú pháp trích dẫn trung lập, và cách đấu nối nó vào một agent hoạt động thực sự.

Kết nối ClinicalTrials.gov v2 + openFDA + ChEMBL thành một endpoint tình báo dược phẩm sạch về giấy phép
Nghiên cứu & phát triển dược phẩm, các startup AI y tế và các nhóm cảnh giác dược đều muốn cùng một thứ: một endpoint kéo về thử nghiệm, nhãn thuốc, biến cố bất lợi và hoạt tính sinh học theo cách sạch về giấy phép. Đây là kiến trúc hoạt động được, cùng những cửa bẫy đã khiến nhiều nhóm bất ngờ khi lên production.

Xây dựng agent nghiên cứu với Web Search + URL Extract (tool use của Claude, từ đầu đến cuối)
Hầu hết các hướng dẫn về 'agent nghiên cứu AI' chỉ dừng ở 'đây là một định nghĩa công cụ'. Bài này giao một agent hoạt động được: đưa vào một câu hỏi, nhận ra một câu trả lời có trích dẫn. Tìm kiếm, trích xuất, suy luận, trích dẫn — tất cả trong chưa tới 120 dòng Python.

Xây dựng tác nhân thẩm định (due diligence) trên hồ sơ SEC (10-K, 10-Q, 8-K, báo cáo lợi nhuận)
Đọc một bản 10-K phần lớn là Ctrl+F. Làm điều đó cho năm mươi công ty là cả một công việc. Hãy thay 80% nhàm chán bằng một tác nhân search-and-extract chạy trên SEC EDGAR — và giữ lại 20% thực sự quan trọng cho nhà phân tích con người.

Vì sao API chỉ nên tính phí khi thành công — Lập luận cho việc tính phí theo HTTP 200
Hầu hết API tính phí trên mọi lệnh gọi có thể tính tiền. Các agent AI liên tục thử lại đối với những dịch vụ upstream không ổn định — nghĩa là mô hình cũ 'luôn tính phí' thực chất đang đánh thuế lên khả năng phục hồi. Đây là lập luận cho việc chỉ tính phí khi HTTP 200, và nó thay đổi điều gì trong cách bạn thiết kế agent.

Tavily vs Exa vs Serper vs API Pick: chọn Web Search API nào cho LLM?
Tavily, Exa, Serper và API Pick đều hứa hẹn là lớp tìm kiếm cho LLM của bạn. Chúng khác nhau rõ rệt về hình dạng đầu ra, bộ lọc và cách tính phí. Đây là so sánh song song từ một người đưa agent ra production.

Firecrawl vs Jina Reader vs API Pick: So sánh các API trích xuất nội dung URL
Nếu bạn từng đưa vào vận hành một agent đọc một danh sách URL rồi tóm tắt chúng, thì bạn đã trả khoản thuế làm sạch URL rồi. Firecrawl, Jina Reader và API Pick Extract giải quyết việc đó theo những cách khác nhau — đây là phần so sánh thực tế.
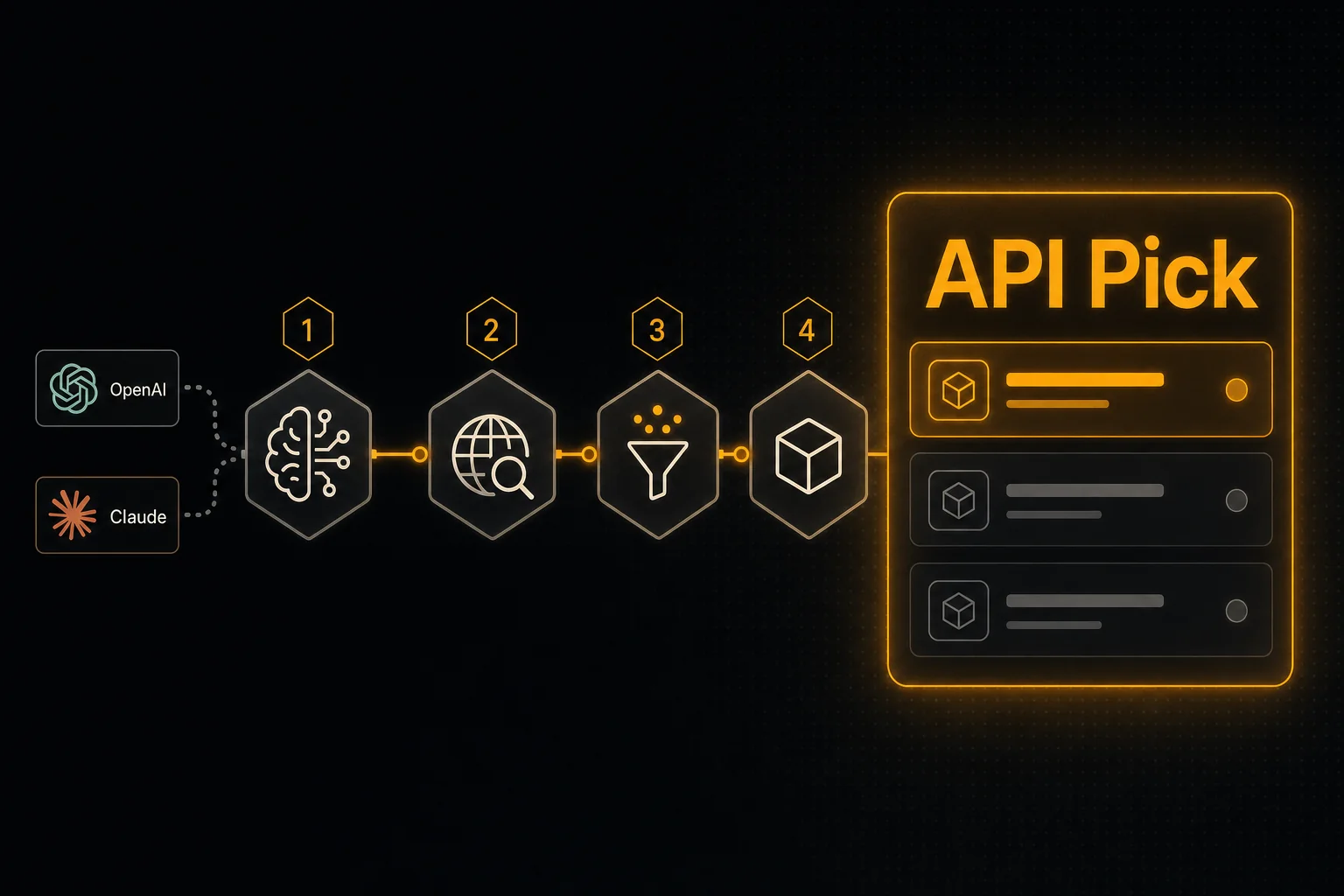
Cách thêm Web Search thời gian thực vào agent OpenAI hoặc Claude trong 4 bước
Muốn agent của bạn dựa câu trả lời trên thông tin hiện tại? Bạn cần đúng hai thứ: một API tìm kiếm trả về các snippet sẵn sàng cho LLM, và một định nghĩa tool mà mô hình có thể gọi. Hướng dẫn này làm cả hai trong 4 bước.

Xây dựng tác nhân tổng hợp tin sáng với News Search API
Mọi founder, PM và nhà phân tích đều muốn cùng một thứ vào 8 giờ sáng: một bản tóm tắt gọn gàng về những gì đã thay đổi qua đêm. Với một News Search API, một LLM và một nền tảng cron qua HTTP, bạn có thể hoàn thành nó trong một buổi chiều.