คู่มือ API สำหรับนักพัฒนาและ AI Agent
บทแนะนำ การเปรียบเทียบ และกรณีการใช้งานสำหรับการอ้างอิงคำตอบ LLM การสร้างเวิร์กโฟลว์ agent และการนำฟีเจอร์ AI ขึ้นใช้งานจริง

วิธีสร้าง Agent วิจัยการลงทุน: ตลาด ปัจจัยพื้นฐาน SEC และข้อมูลเศรษฐกิจใน API เดียว
Agent วิจัยการลงทุนต้องการข้อมูลห้าชั้นที่แตกต่างกัน — ราคา ปัจจัยพื้นฐาน เอกสารยื่น ข้อมูลมหภาค และข่าว — ซึ่งแต่ละอย่างมักเป็นผู้ให้บริการ คีย์ และ schema แยกกัน นี่คือวิธีเชื่อมทั้งห้าไว้หลังชุด endpoint เดียว พร้อมโค้ดที่ใช้งานได้และการคำนวณต้นทุน

สร้าง Agent สำหรับข่าวกรองช่องโหว่และ CVE: รวม CISA KEV, NVD, EPSS และ MITRE ATT&CK ไว้ใน API เดียว
ทุกทีมความปลอดภัยจมอยู่กับ CVE จำนวนมหาศาล สัญญาณที่แท้จริงไม่ใช่ระดับความรุนแรง — แต่คือช่องโหว่นั้นกำลังถูกโจมตีอยู่หรือไม่ และมีโอกาสมากแค่ไหน นี่คือวิธีสร้าง agent ที่หลอมรวม NVD, CISA KEV, EPSS และ ATT&CK เข้าด้วยกันเพื่อตอบคำถามว่า 'ควรแพตช์อะไรก่อน?'

API ข้อมูลตลาดแบบเรียลไทม์สำหรับ AI Agent: หุ้น คริปโต ฟอเร็กซ์ และ ETF ในเอนด์พอยต์เดียว
API ข้อมูลตลาดส่วนใหญ่ถูกสร้างมาเพื่อ dashboard และไปป์ไลน์เชิงปริมาณ ไม่ใช่สำหรับ LLM agent นี่คือสิ่งที่เปลี่ยนไปเมื่อผู้ใช้ของคุณคือโมเดล — การ query ด้วยภาษาธรรมชาติ รูปแบบเดียวสำหรับทุกประเภทสินทรัพย์ การเรียกเก็บเงินแบบคิดเฉพาะเมื่อสำเร็จ — และ API Pick Markets เปรียบเทียบกับผู้เล่นรายเดิมอย่างไร

Company Fundamentals API: งบดุล กระแสเงินสด และการซื้อขายของผู้บริหารสำหรับ Finance Agent
ราคาบอกคุณว่าตลาดคิดอย่างไร ส่วนปัจจัยพื้นฐานบอกว่าตลาดคิดถูกหรือไม่ นี่คือ API ปัจจัยพื้นฐานที่ออกแบบมาสำหรับ AI agent — งบการเงิน เงินปันผล และการซื้อขายของผู้บริหารในหนึ่ง endpoint — และเปรียบเทียบกับ SEC EDGAR แบบดิบและผู้ให้บริการ API งบการเงิน

Economic Data API สำหรับ AI Agent: FRED, BLS, World Bank และ IMF ในการเรียกครั้งเดียว
API ของ FRED นั้นยอดเยี่ยม — และเน้นสหรัฐฯ ขับเคลื่อนด้วยรหัสชุดข้อมูล (series ID) และเป็นหนึ่งในหลายแหล่งข้อมูลมหภาคที่คุณจะต้องใช้ในที่สุด นี่คือ endpoint ข้อมูลเศรษฐกิจที่รวม FRED, BLS, World Bank และ IMF ไว้หลังการเรียกด้วยภาษาธรรมชาติเพียงครั้งเดียวสำหรับ agent ที่เข้าใจภาพมหภาค

Web Search API ที่ดีที่สุดสำหรับ AI Agent ในปี 2026 (เปรียบเทียบ)
Bing Search ถูกปิดตัวลงในปี 2025 และ search API แบบ agent-native กว่าสิบตัวก็แห่กันเข้ามาแทนที่ นี่คือแผนที่เชิงปฏิบัติที่อัปเดตล่าสุดว่าใครคืนค่าอะไร ใครคิดเงินอย่างไร และควรต่อ API ตัวไหนเข้ากับ agent ของคุณ

Exa vs Tavily: ควรเลือก Search API ตัวไหนสำหรับ AI agent ของคุณ? (2026)
Exa และ Tavily คือสองชื่อแรกที่โผล่ขึ้นมาเมื่อคุณต่อการค้นหาเข้ากับ agent ทั้งคู่แก้โจทย์เดียวกันด้วยวิธีที่ตรงข้ามกัน นี่คือการเทียบตัวต่อตัวอย่างตรงไปตรงมา พร้อมรูปแบบ API จริงและราคาปี 2026

Agentic search กับ SERP scraping: ทำไม agent จึงต้องการ API ที่ต่างออกไป
ตลอดยี่สิบปี API ค้นหาหมายถึง 'ขูดหน้าผลลัพธ์ของ Google' AI agent ได้ทลายสมมติฐานนั้นลง นี่คือสิ่งที่ agentic search เป็นจริง ๆ ทำไมมันจึงเกิดขึ้น และเมื่อไรที่โมเดล SERP แบบเดิมยังคงสมเหตุสมผล

API ของ Google Patents ตายแล้ว — 6 ทางเลือกสำหรับการค้นหางานที่มีอยู่ก่อนและการตรวจสอบเสรีภาพในการดำเนินการ
Google Patents Public Datasets ถูกยกเลิกไปโดยไม่มีตัวแทนที่มีเอกสารกำกับ และ USPTO ได้ย้าย PEDS ไปยัง Open Data Portal ใหม่ในช่วงกลางปี 2026 ทำให้ไปป์ไลน์พังระหว่างทาง นี่คือสิ่งที่ใช้งานได้จริงในปี 2026 สำหรับงานด้านงานที่มีอยู่ก่อน, FTO และการวิจัยทรัพย์สินทางปัญญา — หกทางเลือกวางเทียบกัน

วิธีสร้าง agent ทบทวนวรรณกรรมวิทยาศาสตร์โดยไม่โดนจำกัดอัตราการเรียก
ลองสร้าง agent ทบทวนวรรณกรรมบน arXiv + PubMed + Semantic Scholar แบบดิบ ๆ วันนี้ แล้วคุณจะชน 429 ก่อนจะอ่านครบสิบเปเปอร์ นี่คือเหตุผลว่าทำไม rate limit ถึงแย่ลง PaperQA / Undermind ทำอะไรอยู่เบื้องหลังจริง ๆ และแพตเทิร์นที่ใช้งานได้จริงซึ่งรอดผ่านเซสชันทบทวนของจริง
API ของ Polymarket vs Kalshi: คู่มือเปรียบเทียบแบบเคียงข้างสำหรับนักพัฒนา (auth, CLOB, WebSocket, ข้อมูลย้อนหลัง)
Polymarket และ Kalshi รันพื้นฐานเดียวกัน — สัญญาแบบใช่/ไม่ใช่บน CLOB — ผ่าน API ที่แตกต่างกันโดยสิ้นเชิง ฝ่ายหนึ่งบังคับให้ใช้ลายเซ็น EIP-712 และ wallet บน Polygon อีกฝ่ายเป็น endpoint แบบ REST ที่มี FIX เป็นทางเลือก หากคุณกำลังสร้าง agent ทำนาย, bot อาร์บิทราจ หรือมอนิเตอร์ smart money นี่คือคู่มือเปรียบเทียบเคียงข้างที่ควรมีอยู่แล้ว

การค้นคืนคำพิพากษาสหราชอาณาจักรที่ยึดโยงกับการอ้างอิงหลังคดี Ayinde v Haringey
คดี Ayinde v Haringey เปลี่ยนสมการของ AI ด้านกฎหมายในสหราชอาณาจักรภายในชั่วข้ามคืน ทนายความ (barrister) รายหนึ่งอ้างคดีปลอมห้าคดีที่ LLM สร้างขึ้น และถูกส่งเรื่องไปยัง Bar Standards Board การอ้างอิงที่หลอน (hallucinated) ตอนนี้มีผลทางจรรยาบรรณวิชาชีพแล้ว นี่คือคู่มือสำหรับนักพัฒนาในการสร้างการค้นคืนคำพิพากษาสหราชอาณาจักรที่ยึดโยงกับการอ้างอิง — TNA Find Case Law, legislation.gov.uk, การแยกวิเคราะห์การอ้างอิงแบบ neutral citation และวิธีต่อเข้ากับ agent ที่ใช้งานได้จริง

เชื่อม ClinicalTrials.gov v2 + openFDA + ChEMBL เข้าเป็น endpoint สืบค้นข้อมูลยาที่สะอาดด้านลิขสิทธิ์
งาน R&D ยา สตาร์ทอัพด้าน AI การแพทย์ และทีมเฝ้าระวังความปลอดภัยของยา ต่างต้องการสิ่งเดียวกัน: endpoint เดียวที่ดึงข้อมูลการทดลอง ฉลาก เหตุการณ์ไม่พึงประสงค์ และฤทธิ์ทางชีวภาพ มาอย่างสะอาดด้านลิขสิทธิ์ นี่คือสถาปัตยกรรมที่ใช้งานได้จริง พร้อมกับดักที่เคยเล่นงานทีมงานในโปรดักชัน

สร้าง research agent ด้วย Web Search + URL Extract (tool use ของ Claude ตั้งแต่ต้นจนจบ)
บทเรียน 'AI research agent' ส่วนใหญ่จบแค่ที่ 'นี่คือ tool definition' แต่บทเรียนนี้ส่งมอบ agent ที่ใช้งานได้จริง: ใส่คำถามเข้าไป ได้คำตอบพร้อมการอ้างอิงออกมา ค้นหา สกัด ให้เหตุผล อ้างอิง — ทั้งหมดในไม่ถึง 120 บรรทัดของ Python

สร้าง Agent ตรวจสอบสถานะ (Due Diligence) บนเอกสารยื่น SEC (10-K, 10-Q, 8-K, ผลประกอบการ)
การอ่าน 10-K ส่วนใหญ่ก็คือกด Ctrl+F ทำแบบนี้กับห้าสิบบริษัทก็กลายเป็นงานเต็มเวลา แทนที่ 80% ที่น่าเบื่อด้วย agent ค้นหา-และ-สกัดข้อความบน SEC EDGAR แล้วเก็บ 20% ที่สำคัญไว้ให้นักวิเคราะห์ที่เป็นมนุษย์

ทำไม API จึงควรคิดเงินเฉพาะเมื่อสำเร็จ — เหตุผลของการคิดเงินแบบ HTTP 200
API ส่วนใหญ่คิดเงินทุกครั้งที่เรียกแบบเก็บเงินได้ AI agent ลองใหม่กับบริการ upstream ที่ไม่เสถียรอยู่ตลอด — ซึ่งหมายความว่าโมเดลเก่าแบบ 'คิดเงินเสมอ' นั้นแท้จริงแล้วกำลังเก็บภาษีจากความยืดหยุ่น นี่คือเหตุผลของการคิดเงินเฉพาะเมื่อได้ HTTP 200 และสิ่งที่มันเปลี่ยนไปในวิธีออกแบบ agent

Tavily vs Exa vs Serper vs API Pick: ควรเลือก Web Search API ตัวไหนสำหรับ LLM?
Tavily, Exa, Serper และ API Pick ต่างก็สัญญาว่าจะเป็นเลเยอร์การค้นหาให้ LLM ของคุณ แต่ทั้งสี่ตัวแตกต่างกันชัดเจนทั้งรูปแบบผลลัพธ์ ตัวกรอง และวิธีคิดค่าใช้จ่าย นี่คือการเปรียบเทียบเคียงข้างกันจากคนที่ปล่อย agent ขึ้น production จริง

Firecrawl vs Jina Reader vs API Pick: เปรียบเทียบ API สำหรับสกัดเนื้อหาจาก URL
ถ้าคุณเคยปล่อย agent ที่อ่าน URL เป็นรายการแล้วสรุปให้ คุณย่อมเคยเจอ "ภาษีการทำความสะอาด URL" มาแล้ว Firecrawl, Jina Reader และ API Pick Extract แก้ปัญหานี้ต่างกันไป นี่คือการเปรียบเทียบเชิงปฏิบัติ
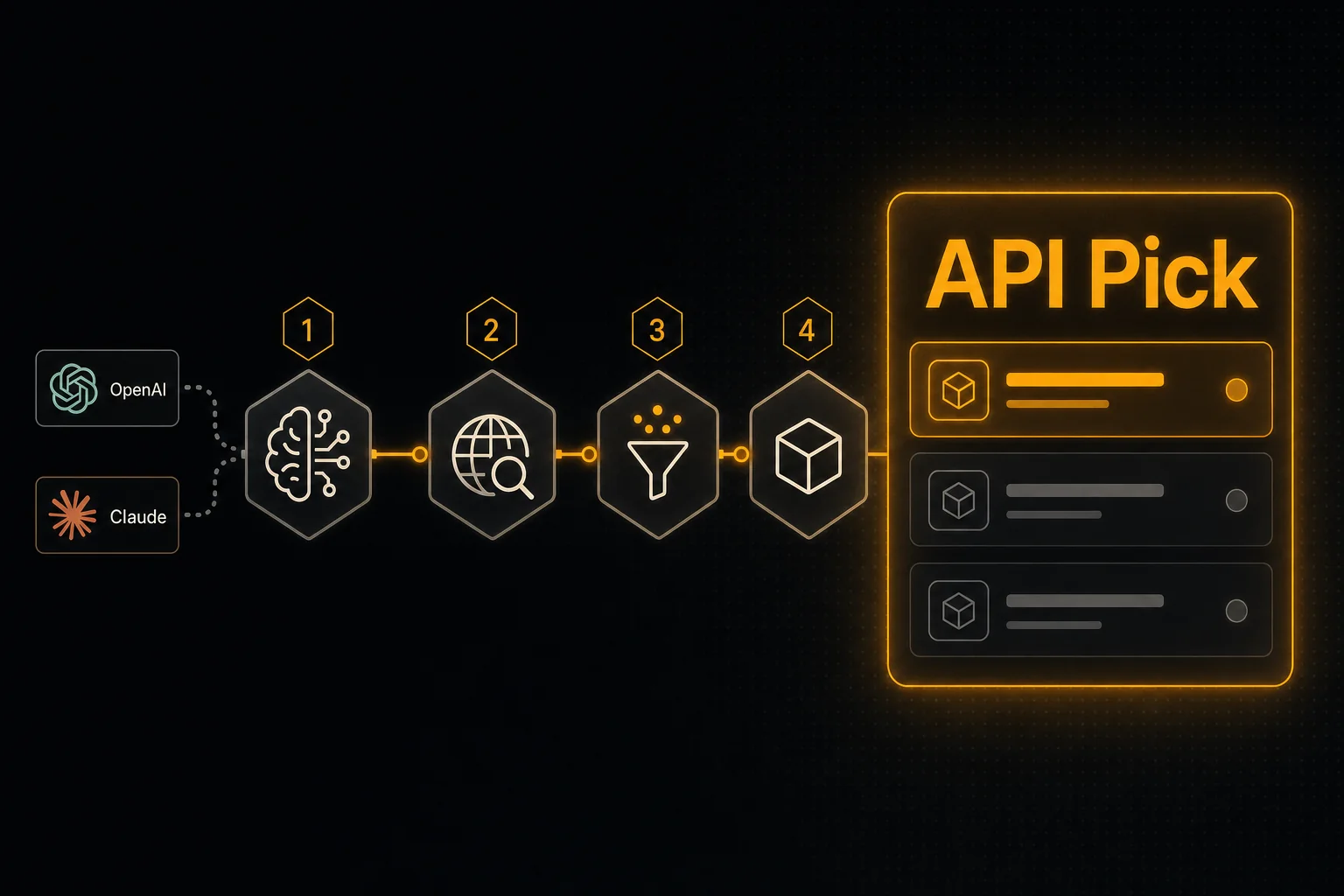
วิธีเพิ่ม Web Search แบบเรียลไทม์ให้กับ agent ของ OpenAI หรือ Claude ใน 4 ขั้นตอน
อยากให้ agent ของคุณอ้างอิงคำตอบจากข้อมูลปัจจุบันใช่ไหม คุณต้องการแค่สองอย่าง: search API ที่คืน snippet พร้อมสำหรับ LLM และนิยาม tool ที่โมเดลเรียกใช้ได้ คู่มือนี้ทำทั้งสองอย่างใน 4 ขั้นตอน

สร้าง Agent สรุปข่าวเช้าด้วย News Search API
ทุกผู้ก่อตั้ง PM และนักวิเคราะห์ต้องการสิ่งเดียวกันตอน 8 โมงเช้า นั่นคือสรุปที่กระชับว่าอะไรเปลี่ยนไปเมื่อคืน ด้วย News Search API, LLM และแพลตฟอร์มที่รัน HTTP-cron ได้ คุณสร้างมันเสร็จได้ในบ่ายเดียว